Yes. There is no doubt that relational databases have an industry monopoly over businesses. Everywhere you go, at some point in your career, you will encounter one, whether you like it or not.
Personally, I have a love-hate relationship with relational databases. When they are structured properly and abstracted just enough for the solution rather than for the sake of architectural purity, they can be fun to work with.
However, for many of us, this is often not the case.
It Made Sense…Back in the Day
Way back in the 80s, relational databases came out as a popular method for structuring data that brought the benefits of persistence and concurrency. SQL was the way to communicate with these databases. If you wanted to integrate your software with a relational database or create meaningful reports, you would need SQL.
However, while SQL has proven to be a useful language, the relational databases it supports are cracking (or have already cracked) under the pressures of growth and business related strategic pivots. Abstracted purity becomes an issue for developers, as there is an impedance mismatch between how the database is structured and the format data required for business to occur.
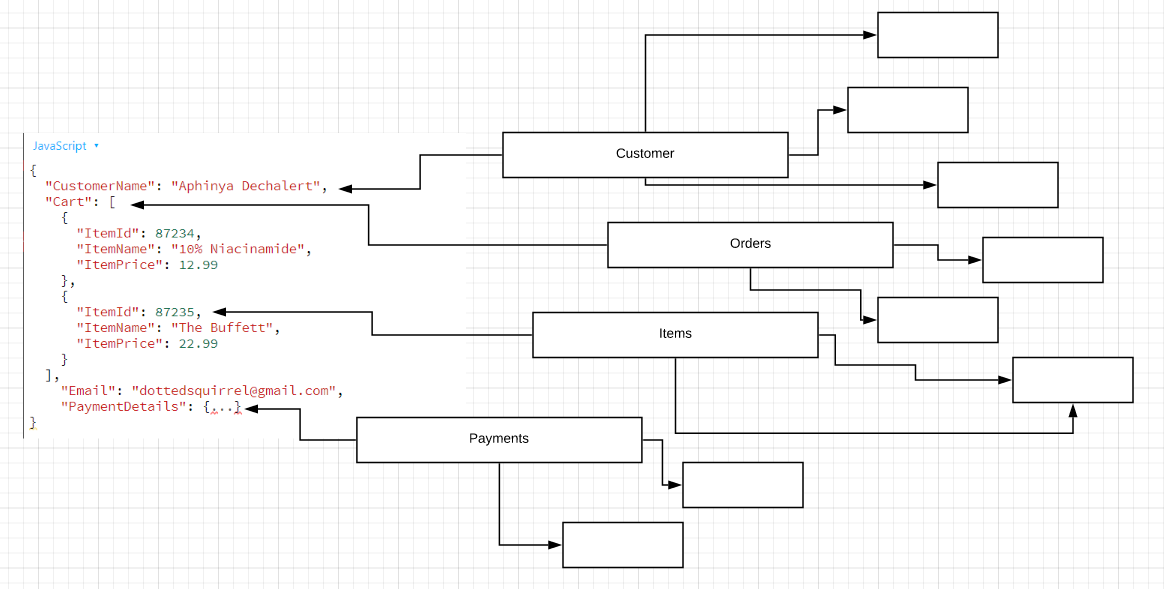
In order to retrieve meaningful data, you have to assemble a lot of things. Then do it all again, but in reverse, when you want to save something. Software construction and relational databases are running on two very different approaches to a particular problem. In turn, they’re creating problems for us when we have to match them — leading to object relational mapping frameworks and an assortment of translation libraries.
#noSQL
Relational databases in general annoyed enough people that it brought the idea of object databases to life in the 90s. One of the purposes of object databases is to save object oriented data in memory as-is, and then put them into the database without having to create maps between data saved and data to be consumed.
But object databases didn’t take root. Or rather, they weren’t allowed to take root, as businesses became locked in through software integrations with relational SQL databases. There was a general relational dominance in the mindset and methodologies of working, with integration as the major determining factor that prevented object databases from rising in popularity.
Despite this, object databases started to become a contender in the data storage space when the Internet required databases to be able to scale in a cost-efficient manner. Scaling up a single box is expensive, with limitations on how big you can get. Scaling through expansion, however, is much more cost-effective and elastic in the ability to grow and downsize. But SQL databases are designed to run on a single box and not clusters of multiple boxes.
Game-changing Challengers
At some point, Google and Amazon decided that they’d had enough. Google came up with Bigtable in 2005, and Amazon released DynamoDB to the public in 2012. MongoDB became open source in 2009, and it made itself even more attractive to developers with queries written in JavaScript. Other tableless databases started to also make an appearance in mainstream knowledge, such as CouchDB, Cassandra, Dynomite and Apache Hbase.
While SQL creates a reasonably standardized way of communicating with relational databases, the listed databases above come with their own requirements and methods of communication. However, they do have a number of things in common, such as being non-relational, fairly open source, cluster friendly, and schema-less.
It was a mixture of these things that eventually inspired a noSQL movement. Fun fact: noSQL was originally a twitter hashtag used by a guy named Johan Oskarsson for organizing an informal meetup in San Francisco.
noSQL databases are being considered by many new businesses and startups, due to their infrastructure scalability. In addition to this, with a data model that favors the requirements of the business rather than the other way around, noSQL databases allow for rapid software development and integrations, in contrast to their SQL based relational database counterparts.
The Four Data Models of noSQL
Data models are what give data the shape it has. In relational models, data is often structured in a two dimensional table with relationships through the usage of keys and associated constraints. With noSQL databases, there are four major methods of thinking about data. Some even go as far as mixing and matching these thought models as needed.
Key value
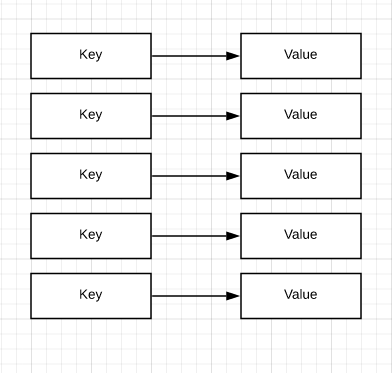
The simplest of the data models is the key value store. The basic idea is that you have a key that indexes your data in the database. The data attached could be anything. In a way, it’s like a persistent hash map that can be distributed across different storage devices.
Some databases allow you to store meta data about the value inside the key, giving you the ability to create complex indexes.
Document
This is probably the most popular of data models, and one we often see as being representative of noSQL. A document can be structured in any manner and can be as complex or as simple as needed. It is considered schema-less and often comes in the form of JSON. You can put anything in it without the database spitting back in anger. We’ve all been there, trying to add something with SQL only to have the database say no.

When you talk to a noSQL database, you can call for a document to be returned, or query into the document structure. This allows you to retrieve portions of the document as needed. While the key value structure just returns the data, the document model gives a bit more flexibility in terms of data transparency.
Column family
Column family can sometimes be confused with relational tables based on how they look. However, they’re not the same in terms of structure. In relational databases, this would be grouped into a table with other potentially non-related data.
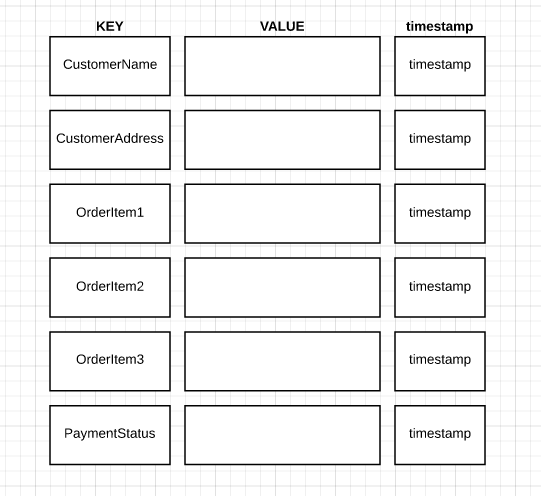
In a column family object, only relevant data exists, and they are structured in a key-pair value. There are actually three columns in total, with one being the column name, the second being the value, and the third being the timestamp. A column family model can be seen as an aggregate of data that is not restricted by a schema.
Graph
In contrast to the other three noSQL models, graph databases present a completely different way of thinking about data. They are very good at moving through the nodes and handling relationships.
While the term relational databases implies that they are good at maintaining relationships in data, you must do quite a bit with foreign keys and complicated joins to extract a set of related data. Too many joins often results in the computer freezing up.
Graph is made specifically to address this problem, and it has its own query language as a response. Graph databases are their own topic, but it’s still good to know about their existence.
When noSQL Isn’t the Right Answer Either
noSQL is great at addressing the scalable infrastructure issue and creaky bridge between data models and software compatibility. However, it’s not the answer to everything. SQL still has a place in our future, whether we like it or not.
Although one of the biggest selling points of noSQL is that it’s schema-less, there is still an implicit schema in the data. SQL databases make relationships and expected data explicit in its entry and create a certain level of consistency. With noSQL databases, it is up to the developer to ensure that data is correct and consistent. There is no secondary checkpoint to enforce such integrity on the data. Your code eventually becomes tied to this implicit schema, and self-monitoring is required to ensure that everything entered is correct.
noSQL also has no enforced concurrency consistency. This means that, at any one point in time, it can only be two out of three things — consistent, available, or partition tolerant. Combined into a handy acronym, this is commonly referred to as the CAP Theorem.
Regardless of structure, if you have a distributed network for your noSQL database, you will get a network partition — i.e. network connection and communication between the different nodes. There’s no point choosing the other two options if you can’t connect to the database itself. This leaves one of two things available — consistent and available. You don’t have this problem in SQL databases.
Another major issue is how to create queries for sets of data. It’s worthwhile to note that noSQL databases often serve the needs of developers; it rarely efficiently serves the needs of analysts. There is no clear language like SQL to interface with the database, and language can vary based on the platform chosen. It is also inefficient to bring sets of data across documents together simply based on how the data itself is structured.
Final Words
There is no database or model to rule all the data — and there shouldn’t be. noSQL was created to solve a problem developers faced through relational databases. Big data is a fairly modern issue that’s only come about at the turn of the century. Relational databases was first proposed back in the early 70s — making the idea behind how data should be efficiently stored over 50 years old.
In contrast, noSQL is much younger and therefore still has much to learn before another solution makes an appearance. But there’s no denying that noSQL makes software development much easier, or that is better at scaling to data requirements. Cloud based services that are available, such as Firebase, BigTable, DynamoDB and hosted MongoDB, make it easier for developers to create interfaces for data.
What database you end up going with for your next green fields project boils down to your requirements. If you’re looking for something that’s easy to interface with and quick to develop, a noSQL database may be a good solution. If you’re looking for something that is familiar and structured with a wide pool of talent that understand what they’re doing, then SQL may be the way to go for stability and strategic purposes.
Whatever kind of database you end up with, remember that it’s not a binary decision. You don’t have to pick one and only one.