We’ve all heard of the DOM at some point. It’s a topic that is quickly brushed over, and there’s not enough discussion of it. The name shadow DOM sounds somewhat sinister — but trust me, it’s not.
The concept of DOMs is one of the foundations of the web and interfaces, and it’s deeply intertwined with JavaScript.
Many know what a DOM is. For starters, it stands for Document Object Model. But what does that mean? Why is it important? And how is understanding how it works relevant to your next coding project?
Read on to find out.
What Exactly Is a DOM?
There’s a misconception that HTML elements and DOM are one and the same. However, they are separate and different in terms of functionality and how they are created.
HTML is a markup language. Its sole purpose is to dress up content for rendering. It uses tags to define elements and uses words that are human-readable. It is a standardized markup language with a set of predefined tags.
Markup languages are different from typical programming syntaxes because they don’t do anything other than create demarcations for content.
The DOM, however, is a constructed tree of objects that are created by the browser or rendering interface. In essence, it acts sort of like an API for things to hook into the markup structure.
So what does this tree look like?
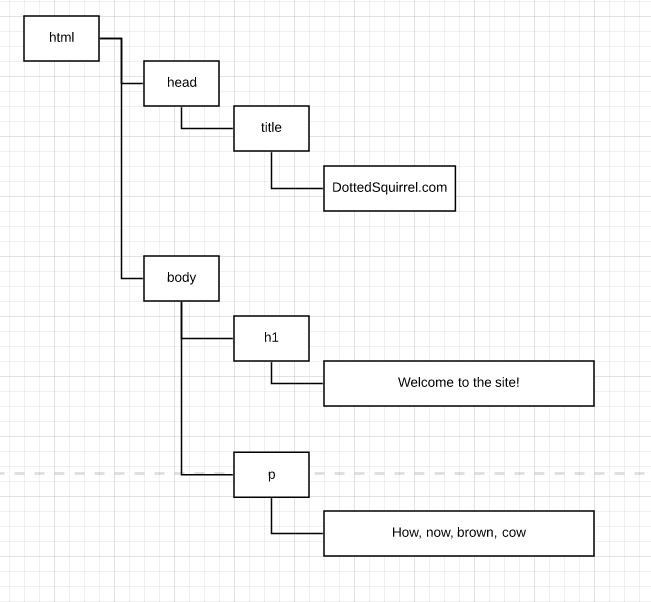
Let’s take a quick look at the HTML below:
<!doctype html>
<html>
<head>
<title>DottedSquirrel.com</title>
</head>
<body>
<h1>Welcome to the site!</h1>
<p>How, now, brown, cow</p>
</body>
</html>
This will result in the following DOM tree.
Since all elements and any styling in an HTML document exist on the global scope, it also means that the DOM is one big globally scoped object.
document in JavaScript refers to the global space of a document. The querySelector() method lets you find and access a particular element type, regardless of how deeply nested it sits in the DOM tree, provided that you have the pathway to it correct.
For example:
This post is for paying subscribers only
Sign up now and upgrade your account to read the post and get access to the full library of posts for paying subscribers only.